Deep learning is a subset of machine learning methods based on neural networks with representation learning. Methods used can be supervised, semi-supervised, or unsupervised. Deep learning architectures have been applied to various fields and are able to extract better features than shallow models through a hierarchy of layers to transform input data into a slightly more abstract representation. The word "deep" refers to the number of layers through which the data is transformed, with deep models being able to learn features effectively. Advances in hardware have driven renewed interest in deep learning, with GPUs playing a crucial role in speeding up training algorithms.
Photo By Sven Behnke - Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=82466022
Introduction
Deep learning is the subset of machine learning methods based on neural networks with representation learning. The adjective "deep" refers to the use of multiple layers in the network. Methods used can be either supervised, semi-supervised or unsupervised.
Deep-learning architectures such as deep neural networks, deep belief networks, recurrent neural networks, convolutional neural networks and transformers have been applied to fields including computer vision, speech recognition, natural language processing, machine translation, bioinformatics, drug design, medical image analysis, climate science, material inspection and board game programs, where they have produced results comparable to and in some cases surpassing human expert performance.
Early forms of neural networks were inspired by information processing and distributed communication nodes in biological systems, in particular the human brain. However, current neural networks do not intend to model the brain function of organisms, and are generally seen as low quality models for that purpose.
Overview
Most modern deep learning models are based on multi-layered neural networks such as convolutional neural networks and transformers, although they can also include propositional formulas or latent variables organized layer-wise in deep generative models such as the nodes in deep belief networks and deep Boltzmann machines.
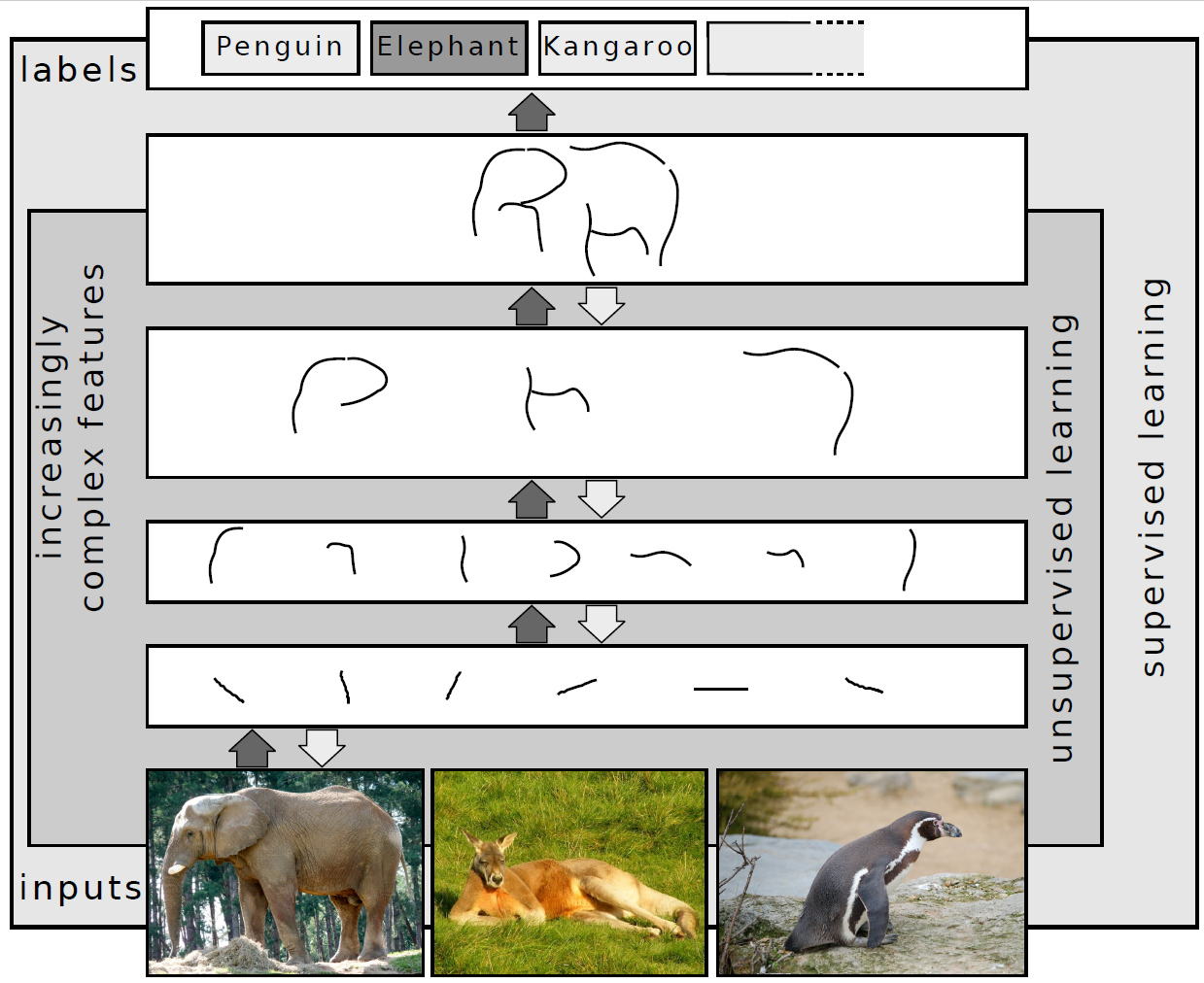
Fundamentally, deep learning refers to a class of machine learning algorithms in which a hierarchy of layers is used to transform input data into a slightly more abstract and composite representation. For example, in an image recognition model, the raw input may be an image (represented as a tensor of pixels). The first representational layer may attempt to identify basic shapes such as lines and circles, the second layer may compose and encode arrangements of edges, the third layer may encode a nose and eyes, and the fourth layer may recognize that the image contains a face.
Importantly, a deep learning process can learn which features to optimally place in which level on its own. Prior to deep learning, machine learning techniques often involved hand-crafted feature engineering to transform the data into a more suitable representation for a classification algorithm to operate upon. In the deep learning approach, features are not hand-crafted and the model discovers useful feature representations from the data automatically. This does not eliminate the need for hand-tuning; for example, varying numbers of layers and layer sizes can provide different degrees of abstraction.
The word "deep" in "deep learning" refers to the number of layers through which the data is transformed. More precisely, deep learning systems have a substantial credit assignment path (CAP) depth. The CAP is the chain of transformations from input to output. CAPs describe potentially causal connections between input and output. For a feedforward neural network, the depth of the CAPs is that of the network and is the number of hidden layers plus one (as the output layer is also parameterized). For recurrent neural networks, in which a signal may propagate through a layer more than once, the CAP depth is potentially unlimited. No universally agreed-upon threshold of depth divides shallow learning from deep learning, but most researchers agree that deep learning involves CAP depth higher than 2. CAP of depth 2 has been shown to be a universal approximator in the sense that it can emulate any function. Beyond that, more layers do not add to the function approximator ability of the network. Deep models (CAP > 2) are able to extract better features than shallow models and hence, extra layers help in learning the features effectively.
Deep learning architectures can be constructed with a greedy layer-by-layer method. Deep learning helps to disentangle these abstractions and pick out which features improve performance.
Deep learning algorithms can be applied to unsupervised learning tasks. This is an important benefit because unlabeled data are more abundant than the labeled data. Examples of deep structures that can be trained in an unsupervised manner are deep belief networks.
History
There were two types of artificial neural network (ANN): feedforward neural networks (FNNs) and recurrent neural networks (RNNs). RNNs have cycles in their connectivity structure, FNNs don't. In the 1920s, Wilhelm Lenz and Ernst Ising created and analyzed the Ising model which is essentially a non-learning RNN architecture consisting of neuron-like threshold elements. In 1972, Shun'ichi Amari made this architecture adaptive. His learning RNN was popularised by John Hopfield in 1982.
Charles Tappert writes that Frank Rosenblatt developed and explored all of the basic ingredients of the deep learning systems of today, referring to Rosenblatt's 1962 book which introduced multilayer perceptron (MLP) with 3 layers: an input layer, a hidden layer with randomized weights that did not learn, and an output layer. It also introduced variants, including a version with four-layer perceptrons where the last two layers have learned weights (and thus a proper multilayer perceptron). In addition, term deep learning was proposed in 1986 by Rina Dechter although the history of its appearance is apparently more complicated.
The first general, working learning algorithm for supervised, deep, feedforward, multilayer perceptrons was published by Alexey Ivakhnenko and Lapa in 1967. A 1971 paper described a deep network with eight layers trained by the group method of data handling.
The first deep learning multilayer perceptron trained by stochastic gradient descent was published in 1967 by Shun'ichi Amari. In computer experiments conducted by Amari's student Saito, a five layer MLP with two modifiable layers learned internal representations to classify non-linearily separable pattern classes. In 1987 Matthew Brand reported that wide 12-layer nonlinear perceptrons could be fully end-to-end trained to reproduce logic functions of nontrivial circuit depth via gradient descent on small batches of random input/output samples, but concluded that training time on contemporary hardware (sub-megaflop computers) made the technique impractical, and proposed using fixed random early layers as an input hash for a single modifiable layer. Instead, subsequent developments in hardware and hyperparameter tunings have made end-to-end stochastic gradient descent the currently dominant training technique.
In 1970, Seppo Linnainmaa published the reverse mode of automatic differentiation of discrete connected networks of nested differentiable functions. This became known as backpropagation. It is an efficient application of the chain rule derived by Gottfried Wilhelm Leibniz in 1973 to networks of differentiable nodes. The terminology "back-propagating errors" was actually introduced in 1962 by Rosenblatt, but he did not know how to implement this, although Henry J. Kelley had a continuous precursor of backpropagation already in 1960 in the context of control theory. In 1982, Paul Werbos applied backpropagation to MLPs in the way that has become standard. In 1985, David E. Rumelhart et al. published an experimental analysis of the technique.
Deep learning architectures for convolutional neural networks (CNNs) with convolutional layers and downsampling layers began with the Neocognitron introduced by Kunihiko Fukushima in 1980. In 1969, he also introduced the ReLU (rectified linear unit) activation function. The rectifier has become the most popular activation function for CNNs and deep learning in general. CNNs have become an essential tool for computer vision.
The term Deep Learning was introduced to the machine learning community by Rina Dechter in 1986, and to artificial neural networks by Igor Aizenberg and colleagues in 2000, in the context of Boolean threshold neurons.
In 1992, Jürgen Schmidhuber also published an alternative to RNNs which is now called a linear Transformer or a Transformer with linearized self-attention (save for a normalization operator). It learns internal spotlights of attention: a slow feedforward neural network learns by gradient descent to control the fast weights of another neural network through outer products of self-generated activation patterns FROM and TO (which are now called key and value for self-attention). This fast weight attention mapping is applied to a query pattern.
The modern Transformer was introduced by Ashish Vaswani et al. in their 2017 paper "Attention Is All You Need". It combines this with a softmax operator and a projection matrix. Transformers have increasingly become the model of choice for natural language processing. Many modern large language models such as ChatGPT, GPT-4, and BERT use it. Transformers are also increasingly being used in computer vision.
In 1991, Jürgen Schmidhuber also published adversarial neural networks that contest with each other in the form of a zero-sum game, where one network's gain is the other network's loss. The first network is a generative model that models a probability distribution over output patterns. The second network learns by gradient descent to predict the reactions of the environment to these patterns. This was called "artificial curiosity". In 2014, this principle was used in a generative adversarial network (GAN) by Ian Goodfellow et al. Here the environmental reaction is 1 or 0 depending on whether the first network's output is in a given set. This can be used to create realistic deepfakes. Excellent image quality is achieved by Nvidia's StyleGAN (2018) based on the Progressive GAN by Tero Karras et al. Here the GAN generator is grown from small to large scale in a pyramidal fashion.
Sepp Hochreiter's diploma thesis (1991) was called "one of the most important documents in the history of machine learning" by his supervisor Schmidhuber. It not only tested the neural history compressor,but also identified and analyzed the vanishing gradient problem. Hochreiter proposed recurrent residual connections to solve this problem. This led to the deep learning method called long short-term memory (LSTM), published in 1997. LSTM recurrent neural networks can learn "very deep learning" tasks with long credit assignment paths that require memories of events that happened thousands of discrete time steps before. The "vanilla LSTM" with forget gate was introduced in 1999 by Felix Gers, Schmidhuber and Fred Cummins. LSTM has become the most cited neural network of the 20th century. In 2015, Rupesh Kumar Srivastava, Klaus Greff, and Schmidhuber used LSTM principles to create the Highway network, a feedforward neural network with hundreds of layers, much deeper than previous networks. 7 months later, Kaiming He, Xiangyu Zhang; Shaoqing Ren, and Jian Sun won the ImageNet 2015 competition with an open-gated or gateless Highway network variant called Residual neural network. This has become the most cited neural network of the 21st century.
In 1995, Brendan Frey demonstrated that it was possible to train (over two days) a network containing six fully connected layers and several hundred hidden units using the wake-sleep algorithm, co-developed with Peter Dayan and Hinton.
Both shallow and deep learning (e.g., recurrent nets) of ANNs for speech recognition have been explored for many years. These methods never outperformed non-uniform internal-handcrafting Gaussian mixture model/Hidden Markov model (GMM-HMM) technology based on generative models of speech trained discriminatively. Key difficulties have been analyzed, including gradient diminishing and weak temporal correlation structure in neural predictive models. Additional difficulties were the lack of training data and limited computing power. Most speech recognition researchers moved away from neural nets to pursue generative modeling. An exception was at SRI International in the late 1990s. Funded by the US government's NSA and DARPA, SRI studied deep neural networks (DNNs) in speech and speaker recognition. The speaker recognition team led by Larry Heck reported significant success with deep neural networks in speech processing in the 1998 National Institute of Standards and Technology Speaker Recognition evaluation. The SRI deep neural network was then deployed in the Nuance Verifier, representing the first major industrial application of deep learning. The principle of elevating "raw" features over hand-crafted optimization was first explored successfully in the architecture of deep autoencoder on the "raw" spectrogram or linear filter-bank features in the late 1990s, showing its superiority over the Mel-Cepstral features that contain stages of fixed transformation from spectrograms. The raw features of speech, waveforms, later produced excellent larger-scale results.
Speech recognition was taken over by LSTM. In 2003, LSTM started to become competitive with traditional speech recognizers on certain tasks. In 2006, Alex Graves, Santiago Fernández, Faustino Gomez, and Schmidhuber combined it with connectionist temporal classification (CTC) in stacks of LSTM RNNs. In 2015, Google's speech recognition reportedly experienced a dramatic performance jump of 49% through CTC-trained LSTM, which they made available through Google Voice Search.
The impact of deep learning in industry began in the early 2000s, when CNNs already processed an estimated 10% to 20% of all the checks written in the US, according to Yann LeCun. Industrial applications of deep learning to large-scale speech recognition started around 2010.
In 2006, publications by Geoff Hinton, Ruslan Salakhutdinov, Osindero and Teh showed how a many-layered feedforward neural network could be effectively pre-trained one layer at a time, treating each layer in turn as an unsupervised restricted Boltzmann machine, then fine-tuning it using supervised backpropagation. The papers referred to learning for deep belief nets.
The 2009 NIPS Workshop on Deep Learning for Speech Recognition was motivated by the limitations of deep generative models of speech, and the possibility that given more capable hardware and large-scale data sets that deep neural nets might become practical. It was believed that pre-training DNNs using generative models of deep belief nets (DBN) would overcome the main difficulties of neural nets. However, it was discovered that replacing pre-training with large amounts of training data for straightforward backpropagation when using DNNs with large, context-dependent output layers produced error rates dramatically lower than then-state-of-the-art Gaussian mixture model (GMM)/Hidden Markov Model (HMM) and also than more-advanced generative model-based systems. The nature of the recognition errors produced by the two types of systems was characteristically different, offering technical insights into how to integrate deep learning into the existing highly efficient, run-time speech decoding system deployed by all major speech recognition systems. Analysis around 2009–2010, contrasting the GMM (and other generative speech models) vs. DNN models, stimulated early industrial investment in deep learning for speech recognition. That analysis was done with comparable performance (less than 1.5% in error rate) between discriminative DNNs and generative models. In 2010, researchers extended deep learning from TIMIT to large vocabulary speech recognition, by adopting large output layers of the DNN based on context-dependent HMM states constructed by decision trees.
Deep learning is part of state-of-the-art systems in various disciplines, particularly computer vision and automatic speech recognition (ASR). Results on commonly used evaluation sets such as TIMIT (ASR) and MNIST (image classification), as well as a range of large-vocabulary speech recognition tasks have steadily improved. Convolutional neural networks were superseded for ASR by CTC for LSTM. but are more successful in computer vision.
Advances in hardware have driven renewed interest in deep learning. In 2009, Nvidia was involved in what was called the "big bang" of deep learning, "as deep-learning neural networks were trained with Nvidia graphics processing units (GPUs)". That year, Andrew Ng determined that GPUs could increase the speed of deep-learning systems by about 100 times. In particular, GPUs are well-suited for the matrix/vector computations involved in machine learning. GPUs speed up training algorithms by orders of magnitude, reducing running times from weeks to days. Further, specialized hardware and algorithm optimizations can be used for efficient processing of deep learning models.